我在掘金上的笔记搬运
这是我参与「第三届青训营 -后端场」笔记创作活动的的第1篇笔记
我是有 Java 基础的前端,这次被朋友拉下来学习后端,来了解下后端的程序设计,从而提高业务对接效率
话不多说,先上手作业第二题目
一个利用现成 API 的词典程序
可是作为第一个作品,我绝对不能做地这么简单!!!
我要做一个基于联想的查词程序!!!
需求分析
- 词典应用,首先使用场景是英译中
- 联想就是输入半个单词,列出所有你可能想输入的单词和其中文解释
- 上网查了下,大部分翻译平台的接口都有 cookie 验证,这对我们长期的稳定功能实现很不友好,但是找不到啥好的平台了,就拿 有道词典 凑合一下了
查看请求
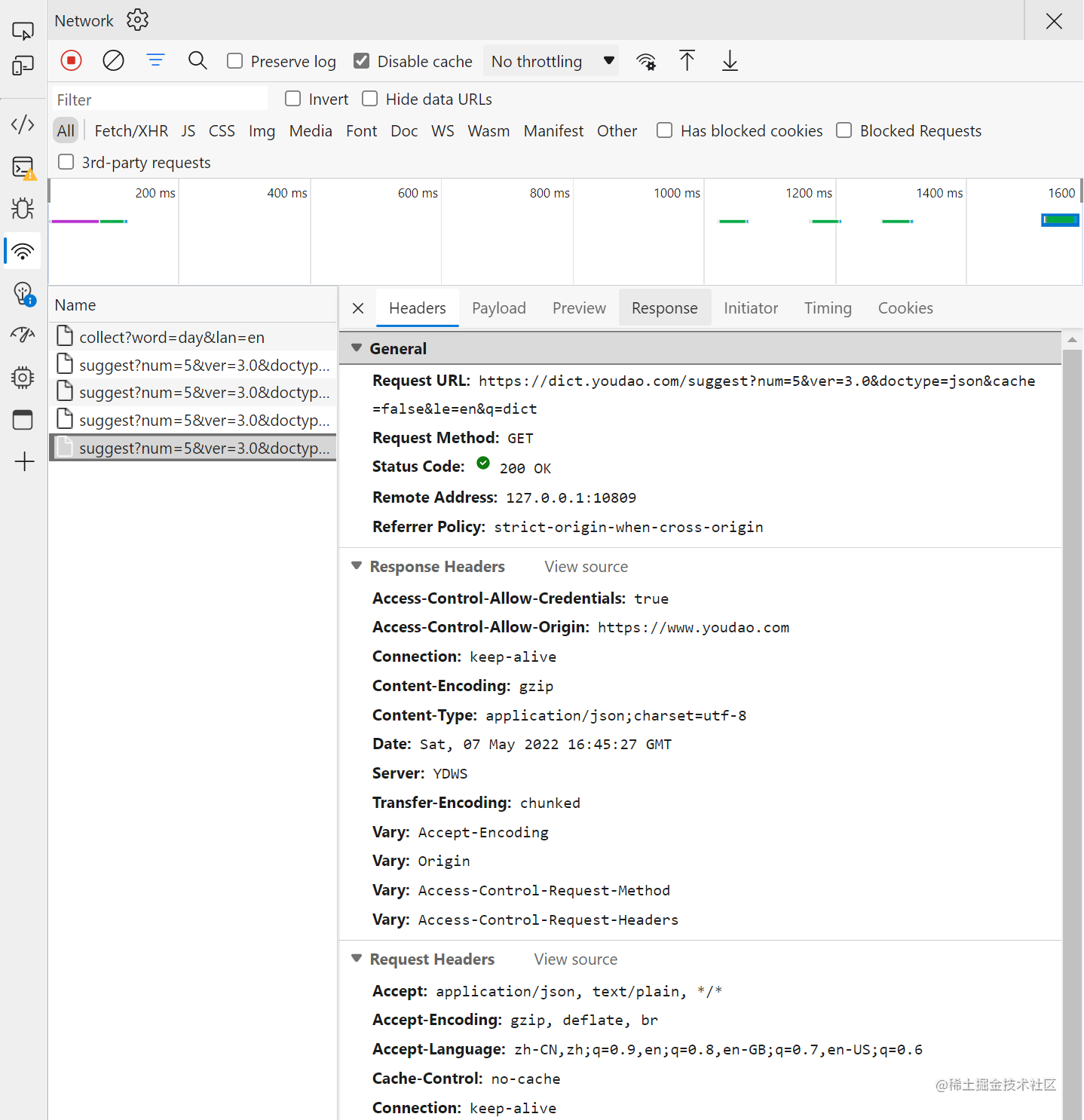
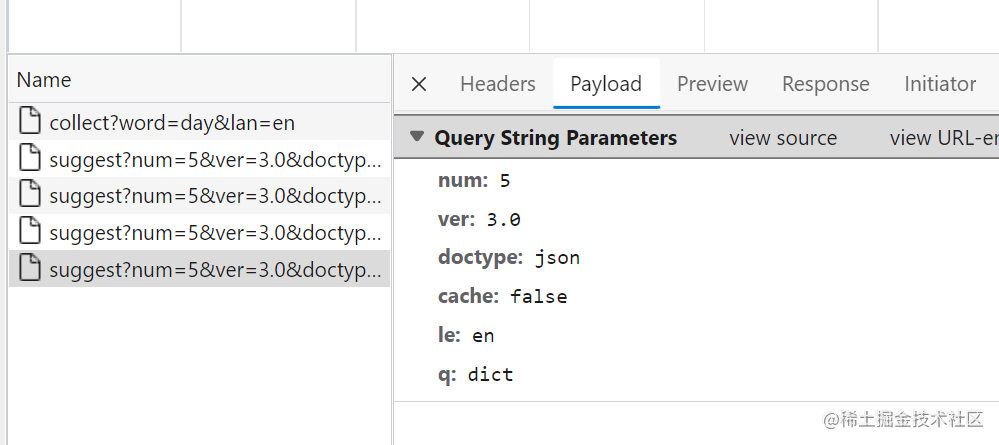
复制了 curl 命令格式之后,转换 go 代码粘贴到文件一气呵成
package main
import (
"fmt"
"io/ioutil"
"log"
"net/http"
)
func main() {
client := &http.Client{}
req, err := http.NewRequest("GET", "https://dict.youdao.com/suggest?num=5&ver=3.0&doctype=json&cache=false&le=en&q=dict", nil)
if err != nil {
log.Fatal(err)
}
req.Header.Set("Accept", "application/json, text/plain, */*")
req.Header.Set("Accept-Language", "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6")
req.Header.Set("Cache-Control", "no-cache")
req.Header.Set("Connection", "keep-alive")
req.Header.Set("Cookie", `已打马`)
req.Header.Set("Origin", "https://www.youdao.com")
req.Header.Set("Pragma", "no-cache")
req.Header.Set("Referer", "https://www.youdao.com/")
req.Header.Set("Sec-Fetch-Dest", "empty")
req.Header.Set("Sec-Fetch-Mode", "cors")
req.Header.Set("Sec-Fetch-Site", "same-site")
req.Header.Set("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36 Edg/101.0.1210.39")
req.Header.Set("sec-ch-ua", `" Not A;Brand";v="99", "Chromium";v="101", "Microsoft Edge";v="101"`)
req.Header.Set("sec-ch-ua-mobile", "?0")
req.Header.Set("sec-ch-ua-platform", `"Windows"`)
resp, err := client.Do(req)
if err != nil {
log.Fatal(err)
}
defer resp.Body.Close()
bodyText, err := ioutil.ReadAll(resp.Body)
if err != nil {
log.Fatal(err)
}
fmt.Printf("%s\n", bodyText)
}
请求头参数很多,自己写的话会麻烦,就使用在线平台转换了,利用现成工具解决问题也是程序员要修炼的
分析处理请求
GET 请求 URL 中的参数就是我们要查的单词,所以得改成从运行命令的第二个参数读取
在main函数开头添加
if len(os.Args) != 2 {
fmt.Fprintf(os.Stderr, `usage: simpleDict WORD example: simpleDict hello`)
os.Exit(1)
}
word := os.Args[1] // word 就是我们要查询的单词
再把 word 拼接到请求 URL 中就能得到返回的 JSON 字符串了,现在我们要做的就是美化工作
分析返回数据

{}
可以看到,联想词和翻译都已经有了
entries数组中的所有元素?拿来吧你!
于是我飞快地写下
for _, item := range bodyText.entries {
fmt.Printf("%s", item)
}
结果。。报错了
我一看,发现bodyText的类型是byte数组,是一个扁平的结构,所以不能直接用 JS 的方式访问成员。
这里扯一嘴,数组的每个元素是这串 JSON 的每个字节,这意味着对于一个汉字需要多个元素来储存,测试了有限个数的汉字,大概是三个?
https://www.zhihu.com/question/20451870
格式化输出
要想访问就得把它反序列化才行,先去写个结构体
type DictReponse struct {
Result struct {
Msg string `json:"msg"`
Code int `json:"code"`
} `json:"result"`
Data struct {
Entries []struct {
Explain string `json:"explain"`
Entry string `json:"entry"`
} `json:"entries"`
Query string `json:"query"`
Language string `json:"language"`
Type string `json:"type"`
} `json:"data"`
}
// some code here...
var dictResponse DictResponse
err = json.Unmarshal(bodyText, &dictResponse)
if err != nil {
log.Fatal(err)
}
for _, item := range dictResponse.Data.Entries {
fmt.Printf("%s : %s\n", item.Entry, item.Explain)
}

滴~ 提前下班